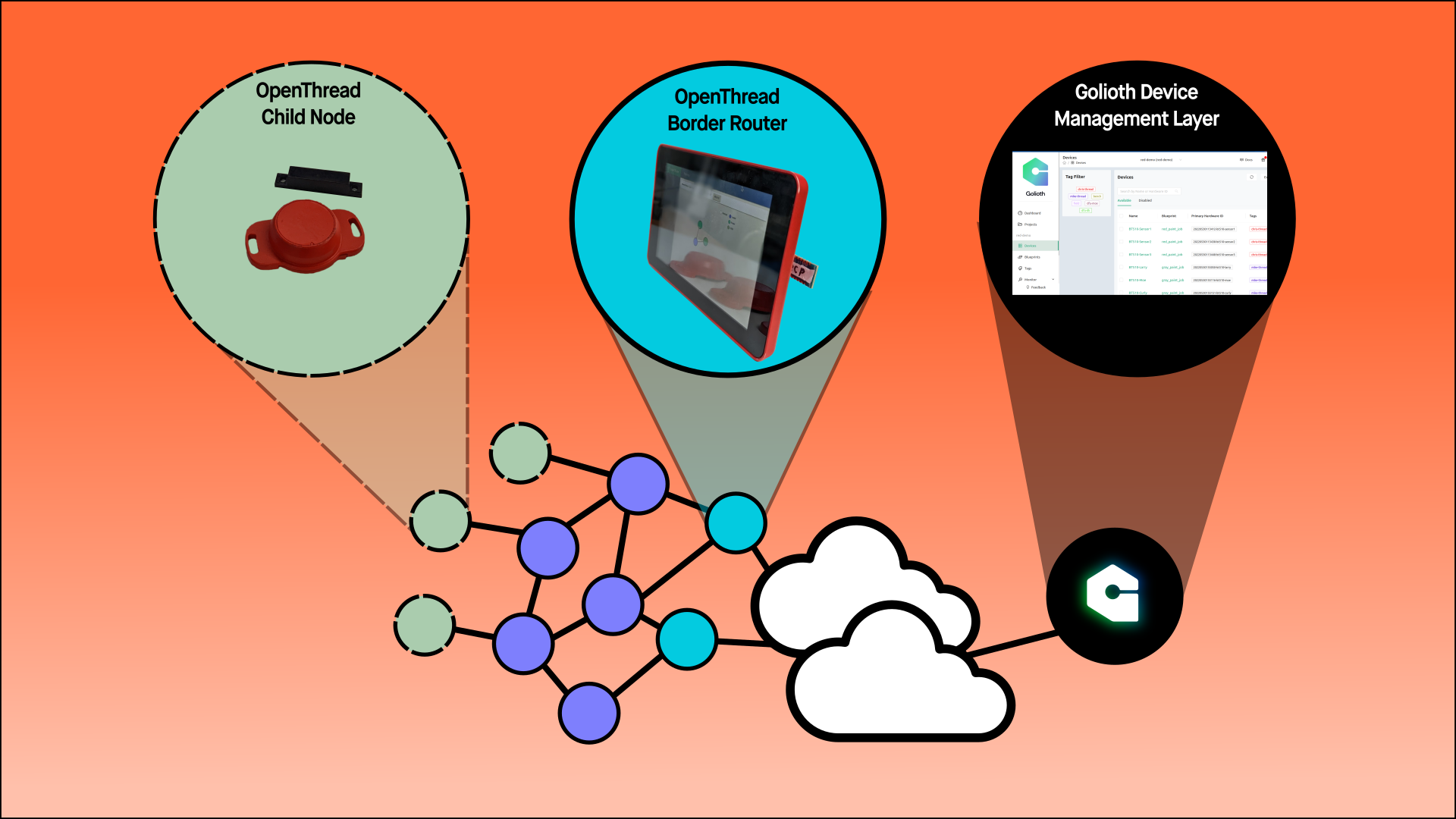
How fast can a new Zephyr user go from zero to successful code compilation?
Golioth continues to invest in Zephyr RTOS capabilities: we have a super strong device SDK that works right on top of the Zephyr SDK, our Reference Designs are built on top of Zephyr, and we continue to train engineers every month on how to get booted quickly with Zephyr. When a fresh face walks through the door of our virtual training, we want to ensure a good experience for training.
In this talk at the Embedded Open Source Summit 2024, Firmware Engineer Mike Szczys describes how we utilize Dev Containers and GitHub Codespaces to provide a pre-installed Zephyr toolchain so that users have a seamless getting-started experience.
An evolution of training
Golioth has held a number of virtual training events using Kasm, something we have written about in the past (and gave a talk about at last year’s EOSS). We liked this method because it provided a pre-installed toolchain in a virtual environment. But it also included a “virtual desktop” environment and was built on top of generic “always on” cloud compute. Any time we did the training we would spin up new EC2 instances to serve users.
The problem is that the utilization was often low and we didn’t keep these resources available. Moreover, the users couldn’t take the work with them: when the session was over, their work was destroyed.
GitHub Codespaces fixes this up front: it’s a configuration script and setup that can deploy a full development environment onto a user’s own GitHub account. If someone wants to continue their work later in the day/week/month, they boot the Codespace back up and pick up where they left off. It’s also possible to utilize the setup to extend to their own projects, or implement interesting remote testing. And you can take it with you, because it’s build on the open standard of development containers.
Development Containers (or just: Dev Containers)
Utilizing Dev Containers only takes a couple of lines of configuration. However, understanding the pieces can be tricky, especially if you’re new to containers generally. Let’s peek at the main .devcontainer file:
{
"image": "golioth/golioth-zephyr-base:0.16.3-SDK-v0",
"workspaceMount": "source=${localWorkspaceFolder},target=/zephyr-training/app,type=bind",
"workspaceFolder": "/zephyr-training",
"onCreateCommand": "bash -i /zephyr-training/app/.devcontainer/onCreateCommand.sh",
"remoteEnv": { "LC_ALL": "C" },
"customizations": {
"vscode": {
"settings": {
"cmake.configureOnOpen": false,
"cmake.showOptionsMovedNotification": false,
"C_Cpp.default.compilerPath": "/opt/toolchains/zephyr-sdk-0.16.3/arm-zephyr-eabi/bin/arm-zephyr-eabi-gcc",
"C_Cpp.default.compileCommands": "/zephyr-training/app/build/compile_commands.json",
"git.autofetch": false
},
"extensions": [
"ms-vscode.cpptools-extension-pack",
"nordic-semiconductor.nrf-devicetree",
"nordic-semiconductor.nrf-kconfig"
]
}
}
}
The top 3 lines of the .devcontainer file we use for training includes 3 critical elements:
- A base level image with Zephyr pre-installed on top of a minimal Linux environment
- Where to mount the local workspace folder inside this container
- The name of the workspace folder and where to drop the user when they boot a container
A critical element having the toolchain pre-installed on a Debian image. The nice part is that you can utilize others’ containers, including ours! If you want to customize containers for your own builds, you might need to learn some new items.
Other customizations allow you to set up how you’d like VS Code to look and which extensions you’d like to have available on boot.
Extending with onCreateCommand.sh
You can add other capabilities once the box has been initiated and is building. This includes pulling in repository information and setting up .bashrc elements that you might find useful from the command line.
#!/bin/bash west init -l app west update west zephyr-export pip install -r deps/zephyr/scripts/requirements.txt echo "alias ll='ls -lah'" >> $HOME/.bashrc west completion bash > $HOME/west-completion.bash echo 'source $HOME/west-completion.bash' >> $HOME/.bashrc history -c
It’s key that the west environment was set up in the initial container, because this now utilizes those tools just like you would when setting up a local Zephyr environment on your computer using our docs.
Binary Downloads As The Main Output
If there’s one argument against this method, it’s that the output of the build is not directly loaded to your development board. We’re working on some capabilities to extend that (see the video for more details), but right now you need to download the binary (zephyr.hex) and load it to your board using a programming tool like nRF Connect For Desktop. That makes this method less optimal for rapid fire debugging. However, it’s possible to debug your program using GDB or something like Segger Ozone. It’s not the same “click to debug” experience that many hardware and firmware engineers are used to from vendor IDEs. We think the ability to get started in 60 seconds is worth the tradeoff.
Slides
View Mike’s slides below and watch the video for an in-depth look at how to create your own Codespaces installation and start with Zephyr today.