Today, we are thrilled to announce the launch of Pipelines, a powerful new set of features that redefines how you manage and route your IoT data on Golioth. Pipelines is the successor to our now-deprecated Output Streams and represents a significant upgrade in our functionality, scalability and user control.
Two years ago, we introduced Output Streams to seamlessly connect IoT data to various cloud services like AWS SQS, Azure Event Hubs, and GCP PubSub. This enabled Golioth users to efficiently stream sensor data for real-time processing, analytics, and storage, integrating easily with their existing cloud infrastructure.
Since then, we’ve gathered extensive feedback, and now we’re excited to introduce a more versatile solution for data routing: Pipelines. Previously, all stream data had to flow into LightDB Stream and conform to its JSON formatting requirements, which was restrictive for those with regulatory and data residency needs. With Pipelines, you can direct your data to LightDB Stream, your own database, or any other destination, in any format you choose.
Pipelines also introduces filtering and transformation features that simplify or even eliminate backend services through low-code configuration. Configurations are stored and managed as simple YAML files, making them easily deployable across multiple projects without manual recreation. This approach allows you to version your data routing configurations alongside your application code.
Internally, Pipelines architecture is designed to support our future growth, enabling us to scale our data routing capabilities to billions of devices. This robust foundation allows us to quickly iterate and add new features rapidly, ensuring that our users always have access to the most powerful and flexible data management tools available.
All Golioth users can start taking advantage of Pipelines today. Projects that were previously only using LightDB Stream and did not have any Output Streams configured have been automatically migrated to Pipelines. Users in those projects will see two pipelines present, which together replicate the previous behavior of streaming to LightDB Stream. These pipelines can be modified or deleted, and new pipelines can be added to support additional data routing use-cases.
Projects with Output Streams configured will continue using the legacy system, but can be seamlessly migrated to Pipelines with no interruptions to data streaming. To do so, users in those projects must opt-in to migration.
New projects created on Golioth will have a minimal default pipeline created that transforms CBOR data to JSON and delivers it to LightDB Stream. This pipeline is compatible with Golioth firmware examples and training, but may be modified or removed by a user if alternative routing behavior is desired.
Pipelines are especially advantageous for users with specific data compliance requirements and those transmitting sensitive information, such as medical device products. Removing the requirement of routing data through LightDB Stream, where it is persisted on the Golioth platform, provides two main benefits:
- Regulatory Compliance: Users can route data to their own compliant storage solutions, making it suitable for many sensitive applications that require data not be persisted on other third-party platforms.
- Cost Savings: For users who do not need data persistence, routing data directly to other destinations can avoid the costs associated with streaming data to LightDB Stream. This flexibility allows for more efficient and cost-effective data management.
Getting Started with Pipelines
Alongside the launch of Pipelines, we have also released a new version of the Golioth Firmware SDK, v0.13.0 , which introduces new functionality to support streaming arbitrary binary data to destinations that support it. Previously, only CBOR and JSON data could be streamed to Golioth, as everything flowed through LightDB Stream, which only accepts JSON data. Now, rather than streaming data to LightDB Stream, data is sent to the Golioth platform and routed to its ultimate destination via the pipelines configured in a project. Devices using previous versions of the Golioth Firmware SDK will continue working as expected.
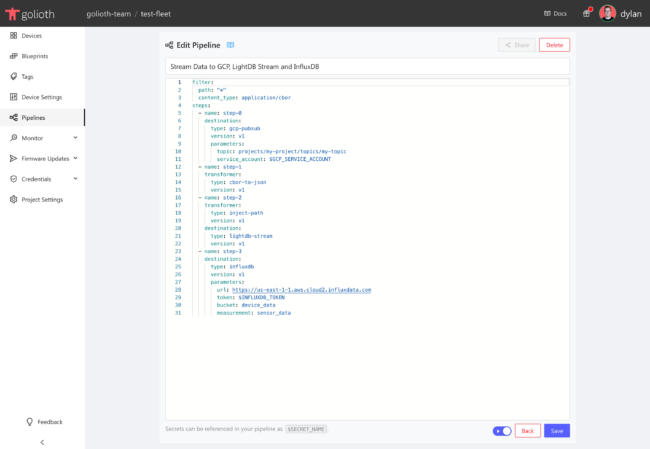
Pipelines can be configured in the Golioth Console using YAML, which defines filters and steps within your pipeline. Here’s an example:
filter:
path: "*"
content_type: application/cbor
steps:
- name: step-0
destination:
type: gcp-pubsub
version: v1
parameters:
topic: projects/my-project/topics/my-topic
service_account: $GCP_SERVICE_ACCOUNT
- name: step-1
transformer:
type: cbor-to-json
version: v1
- name: step-2
transformer:
type: inject-path
version: v1
destination:
type: lightdb-stream
version: v1
- name: step-3
destination:
type: influxdb
version: v1
parameters:
url: https://us-east-1-1.aws.cloud2.influxdata.com
token: $INFLUXDB_TOKEN
bucket: device_data
measurement: sensor_data
This pipeline accepts CBOR data, delivers it to GCP PubSub, before transforming it to JSON and delivering it to both LightDB Stream (with the path injected) and InfluxDB. This is accomplished via three core components of Pipelines.
Filters
Filters route all or a subset of data to a pipeline. Currently, data may be filtered based on path and content_type. If either is not supplied, data with any value for the attribute will be matched. In this example, CBOR data sent on any path will be matched to the pipeline.
filter:
path: "*"
content_type: application/cbor
Transformers
Transformers modify the structure of a data message payload as it passes through a pipeline. A single transformer may be specified per step, but multiple steps can be chained to perform a sequence of transformations. This transformer will convert data from CBOR to JSON, then pass it along to the next step.
- name: step-1
transformer:
type: cbor-to-json
Destinations
Destinations define where the transformed data should be sent. Each step in a pipeline can have its own destination, allowing for complex routing configurations. When a step includes a transformer and a destination, the transformed data is only delivered to the destination in that step. This destination sends JSON data to LightDB Stream after nesting the object using the message path. The next step receives the data as it was prior to the path injection.
- name: step-2
transformer:
type: inject-path
destination:
type: lightdb-stream
version: v1
The full list of Output Stream destinations is now available as Pipelines destinations (with more to come):
- Azure Event Hub
- AWS SQS
- Datacake
- GCP PubSub
- InfluxDB
- MongoDB Time Series
- Ubidots
- Webhooks
For detailed documentation visit, visit our Pipelines Documentation.
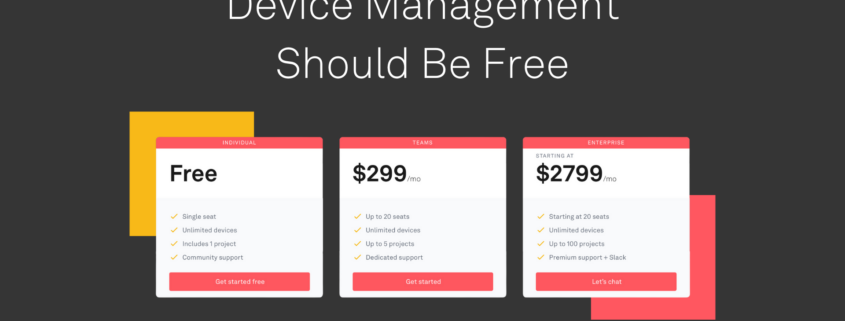
Updated Pricing Model
We’re keeping the same usage-based pricing as Output Streams but also introducing volume discounts. We want to emphasize transparent pricing optimized for MCUs and are revising the pricing structure for Pipelines to accommodate a wider range of data usage patterns, ensuring affordability and predictability in billing for both low and high bandwidth use cases while ensuring customers with large fleets of devices can enjoy discounts that come with scale.
| Data routed to External Pipelines Destination |
|
| Data Volume (per Month) |
Per MB Price ($) |
| 0 – 1 GB |
$0.40 |
| 1 – 10 GB |
$0.34 |
| 10 – 50 GB |
$0.28 |
| 50 – 150 GB |
$0.22 |
| 150 – 300 GB |
$0.16 |
| 300 – 600 GB |
$0.10 |
| 600 – 1 TB |
$0.04 |
| 1 TB+ |
$0.01 |
| Data routed to LightDB Stream |
|
| Data Volume (per Month) |
Per MB Price ($) |
| 0-1 TB + |
$0.001 |
The first 3MB of usage for Pipelines is free, allowing users who are prototyping to do so without needing to provide a credit card. This includes usage routing data to LightDB Stream through Pipelines.
For full details, visit Golioth Pricing.
Pipelines marks a significant step forward in Golioth’s IoT data routing capability, offering a new level of flexibility and control. We’re excited to see how you’ll use Pipelines to enhance your IoT projects. For more details and to get started, visit our Pipelines Documentation.
With our new infrastructure, we can rapidly add new destinations and transformations, so please let us know any you might use. Additionally, we’d love to hear about any logic you’re currently performing in backend services that we can help you streamline or even delete. If you have any questions or need assistance, don’t hesitate to reach out. Contact us at [email protected] or post in our community forum. We’re here to help!
Migration from Output Streams to Pipelines
As previously mentioned, projects currently using Output Streams will continue to leverage the legacy infrastructure until users opt-in to migration to Pipelines. We encourage users to try out Pipelines in a new project and opt-in existing projects when ready. Output Streams does not currently have an end of life date but we will be announcing one soon.
Stay tuned for more updates and happy streaming!