TL;DR: Golioth uses CoAP because we care about performance, acknowledge that IoT architectures are heterogeneous, and believe that the definition of performance depends on the specifics of the given architecture.
If you’ve ever used the Golioth platform, or have even just toured through our documentation, you’ve likely encountered some mention of the Constrained Application Protocol (CoAP). While perhaps less familiar than other application layer protocols, such as HTTP, CoAP has established a foothold in the internet of things (IoT) space due to design decisions that allow its usage in highly constrained environments.
CoAP takes a unique approach that makes it well-suited for a world in which data flows from tiny devices, to data centers, and back again. It’s certainly not the only option for a protocol designed for performance. Today we’re going to do an overview of the problem space, a high-level description of CoAP, and a preview of where we are going. In the future, we’ll explore why we have standardized on CoAP at Golioth by demonstrating its impact in real environments.
What Do You Mean by “Constrained”?
Describing a device, network, or environment as “constrained” tells you very little about its actual attributes. Constrained only means that there are some limitations. But limitations may be imposed on any number of vectors. Some of the most common we encounter with users of Golioth’s platform include:
- Power
- Compute
- Memory
- Network
Devices fall into two broad categories with respect to power: those with continuous access and those without. The latter group consists of a wide range of devices:
- Some have access to power on an intermittent, but relatively frequent basis.
- Some need to operate for years on a single battery.
Conserving power is crucial for devices across the spectrum, and at the extreme end, it may be the foremost priority.
Compute typically refers to the raw performance of one or more CPUs on a device, as measured by their clock speed. These speeds may be orders of magnitude slower than the CPUs in devices we use on a daily basis, such as the smartphone in your pocket. Compute power limitations restrict the types of computation a device can perform. As a result, device operations need to be highly optimized.
Memory impacts both the amount of data that can be processed on a single device, as well as the size of the firmware image that runs on the device. The former may be constrained by the amount of volatile memory (e.g. SRAM, DRAM), on the device, while the latter is primarily constrained by the non-volatile memory (e.g. flash).
🔥🔥🔥 A brief rant on ROM 🔥🔥🔥
Read-Only Memory (ROM) has become synonymous with non-volatile memory, which, unfortunately has very little to do with whether the memory is write-able or not. Even when we are being more specific, using terms like Electronically Erasable Programmable Read-Only Memory (EEPROM), the very name is a contradiction. How is it read-only if we can also write to it? What we really mean to say is that we can read and write to it but it doesn’t go away when we lose power, and it is typically quite slow. In this series, we’ll do our best to use terminology that is specific about the exact type of memory we are interacting with.
Network relates to both the physical capabilities of the device, and the environment in which it is deployed. A device may lack the necessary hardware to communicate on a given type of network due to size or cost constraints. Regardless of the innate capabilities of a device, it might have trouble accessing networks, or the network may be noisy or unreliable.
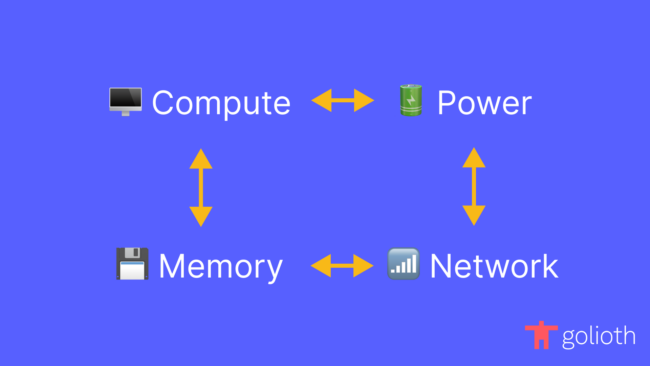
Some constraints can change, but changing one will frequently impact others. For example, increasing the clock speed of a CPU will likely cause it to consume more power. There are always non-technical constraints at play as well, such as the cost of the device. Users of Golioth’s platform have to balance the trade-offs and make compromises, but they shouldn’t need to worry about how Golioth fits into their system with the decisions they make today, or the ones they make tomorrow.
Improving Performance in a Constrained Environments
IoT applications typically are interested in data: collecting it, processing it, sending it, and ultimately using it to make some decision. The constraints placed on devices impacts how an organization may go about performing these operations, and there are a few options available to them.
In an environment where devices are constrained on multiple dimensions, it may make sense to collect less data. While it may be nice to collect a reading from a sensor every minute, it may be acceptable to do so every hour. This is a powerful option because it typically results in positive downstream effects throughout the system. For example, choosing to collect a reading every hour means that a device can conserve more power by going to sleep for longer periods of time. It also means that less data will be sent over the network, and performing retries will be less of a concern due to the decreased number of messages being delivered.
Another option is to change where data is being processed. For Devices with continuous access to power and large amounts of memory, but operating on a constrained network, it may be advantageous to clean and aggregate the data before attempting to deliver it to its final destination. Simple sampling of data can go a long way to reduce network data usage in more constrained devices.
The final option is to send less data. While the previous two solutions also have an impact in this domain, you can send less data while collecting the same amount and doing most of the processing at the final destination. One mechanism for doing so is lossless compression. Implementing compression may come at the cost of larger firmware images and more power usage, but could drastically reduce the bandwidth used by a given application.
For those of you saying “compression is a form of processing!” — touche. However, we will use “processing” to mean changing the data in an irreversible manner in this post, whereas “compression” will be used to mean changing the data in a way that all of it can be recovered.
However, network connections are not only about payloads. Different protocols incur varying amounts of overhead to establish a connection with certain properties. If reliable transmission is required, more data will be required. The same is true to establish a secure connection.
In the end, developing solutions is not so different from adjusting the constraints of a system. There are a web of complex trade-offs to navigate, all creating side-effects in other parts of the system.
Performance is Flexibility
With so many dimensions in play, performance does not mean one thing in the world of IoT.
Or any other world, for that matter. I don’t care what the README’s of all the “blazing fast” libraries say.
Rather, a solution that focuses on performance is one that fits the constraints of the domain. When a resource is abundant, it should be able to consume more of it in favor of consuming less of a scarce one. When scarcity changes, the solution should be able to adapt.
At Golioth, we not only have to ensure that our platform accommodates the needs of any single organization, but also many different organizations at once. This means integrating with countless devices, working in all types of environments, and being able to provide a consistent user experience across heterogeneous system architectures.
At the core of achieving this goal are protocols. IoT products are nothing without the ability to communicate, but they introduce some of the most difficult scenarios in which to do so. Some protocols are better fits than others given some set of constraints, but few protocols are able to adapt to many different scenarios. The Constrained Application Protocol (CoAP) is unique in its ability to provide optimal trade-offs in many different environments.
The Constrained Application Protocol
CoAP was developed to accommodate many of the scenarios already explored in this post. While built from the ground up for a specific use-case, most folks who have used the internet before will find its design familiar. This is primarily due to the broad adoption of Representational State Transfer (REST) in the design of Hypertext Transfer Protocol (HTTP) APIs. CoAP aims to provide a similar interface in environments where usage of a full HTTP networking stack would not be feasible.
At the core of the CoAP architecture is a simple concept: allowing for reliability to be implemented at the application layer. This decision opens up a world of possibilities for application developers, allowing them to choose the guarantees that are appropriate for their use-case. The first level in which this philosophy is reflected is the usage of the User Datagram Protocol (UDP) as the default transport layer.
UDP and the Transmission Control Protocol (TCP) are the primary Layer 4 protocols in the OSI model, on which many higher layer protocols are built. The foundational difference between UDP and TCP is that the latter guarantees reliable, in-order delivery of packets, while the former does not. While this a favorable attribute of TCP, it also comes at a cost. In order to provide these guarantees, there is additional overhead in the handshake that sets up the connection between two endpoints, and larger packet headers are required to supply metadata used to implement its reliability features.
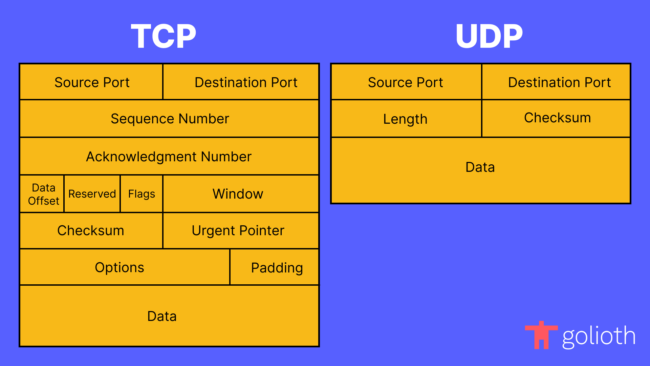
However, saying that UDP is always more performant than TCP would be incorrect. In some cases, such as the frequent transmission of small payloads on an unconstrained network where ordering is critical, the overhead of establishing a reliable connection and the congestion control features that TCP implements may actually result in fewer round-trips and less data being sent over the wire than when using some protocols that layer on top of UDP. That is not to say that similar characteristics cannot be achieved with UDP — it just doesn’t provide them out of the box. This is where CoAP shines: it optionally provides some of the features of TCP, while empowering the application developer to choose when to employ them.
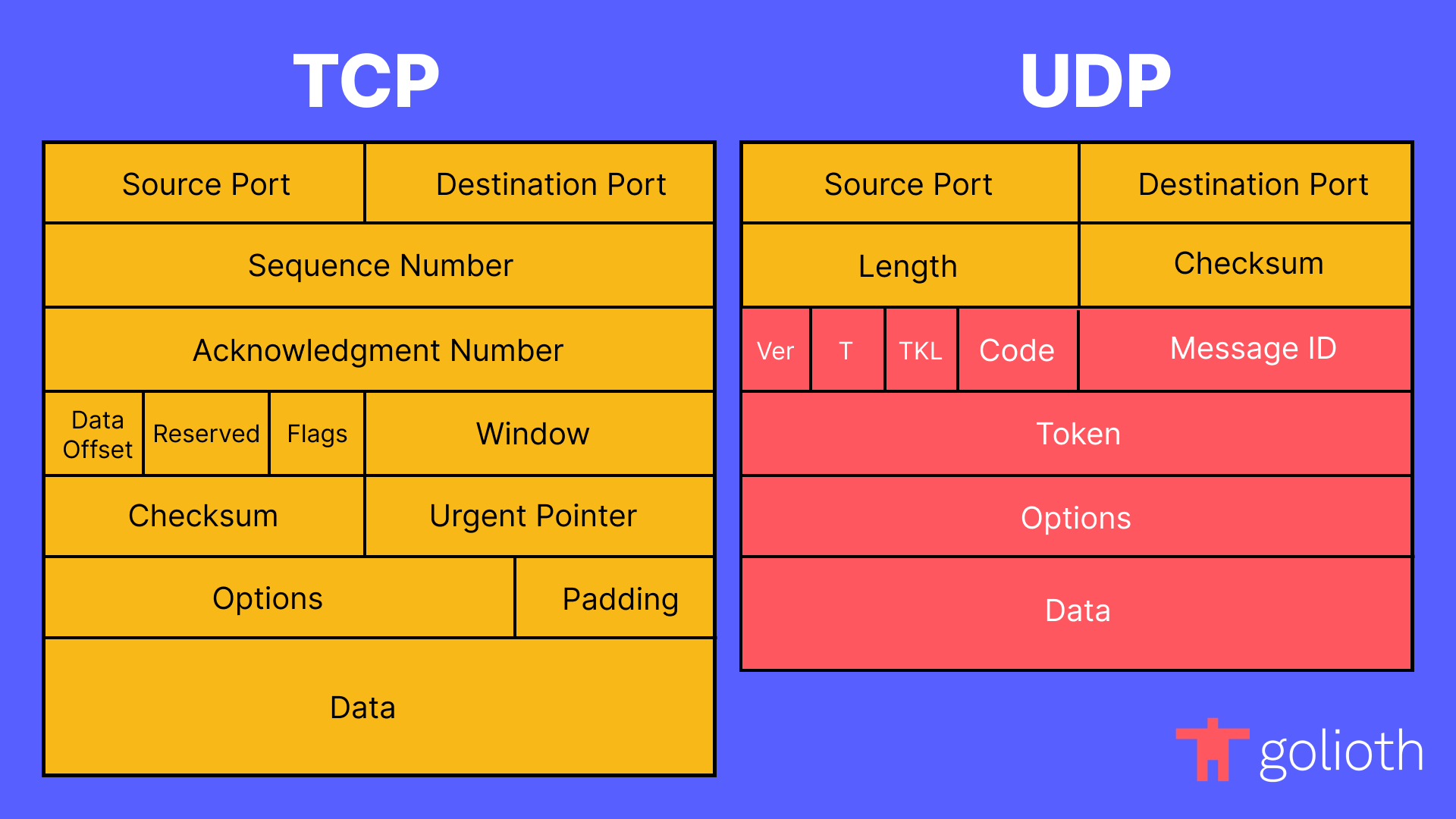
This is accomplished through the use of Confirmable (CON) and Non-confirmable (NON) message types, and the usage of Message IDs. It is common for applications to use both reliable and unreliable transmission when sending messages over CoAP. For example, it may be critical that every message containing a reading from a certain sensor is delivered from a device to a data center. It also could be configured to tolerate dropping messages containing information about the battery power remaining on the device.
Even though CoAP is designed to layer on top of UDP by default, it is capable of being layered on top of other transports — even TCP itself. When the underlying transport provides reliability, the CoAP implementation can strip out extraneous metadata, such as the Message ID, and eliminate application level Acknowledgement (ACK) messages altogether. Additionally, because of the adoption of REST concepts, proxies that translate from CoAP to HTTP, and vice versa, can do so without maintaining additional state. These attributes make CoAP a protocol that is capable of effectively bridging between constrained and unconstrained environments.
“All Others Must Bring Data”
If you search for protocol comparisons on the internet, you are bound to find a slew of high-level overviews that fail to bring data to justify many of the claims made. At Golioth, we believe in validating our assumptions with real-world examples that map to actual use-cases. In this post we have only scratched the surface of how CoAP works. We hope to dive into more detail, exploring environments with each of the enumerated constraints and how Golioth’s platform behaves in them.
In the mean time, sign up for Golioth’s free Dev Tier today and try it out with your unique IoT application!

Excuse me, but why you decided to use coap instead of mqtt? After some researches my company found that mqtt is more suitable than coap. Thanks for creating this awesome platform.
This is going to be a future entry into this blog series. We’d love to hear what your company found as reasons for choosing MQTT over CoAP!
@ChrisGammell I’ll gather all the researches we made then I’ll tell you why we choose MQTT over CoAP.